|
AI deep learning expert and University of Montreal Professor Yoshua Bengio talks about deep learning—what Deep Learning and AI are, how Deep Learning got there, where it’s going, and how you can learn more about it. He discusses the latest in neural nets, unsupervised learning, generative adversarial networks, soft attention, optimization, and more. Yoshua Bengio (born 1964 in France) is a Canadian computer scientist, most noted for his work on artificial neural networks and deep learning. Yoshua Bengio is Full Professor of the Department of Computer Science and Operations Research, head of the Montreal Institute for Learning Algorithms (MILA), CIFAR Program co-director of the CIFAR program on Learning in Machines and Brains, Canada Research Chair in Statistical Learning Algorithms. His main research ambition is to understand principles of learning that yield intelligence. He teaches a graduate course in Machine Learning and supervises a large group of graduate students and post-docs. His research is one of the most cited scientists in the field of deep learning. Jul 2017
0 Comments
 The video analytics industry is still shaking off the reputational damage that it sustained as a result of promising too much and delivering too little in the past. For years, the reliability of video analytics has been extremely variable, with vendors struggling to develop algorithms that could function in complex scenes. The industry has come a long way in recent years, and the capabilities of more conventional video analytics have steadily increased. However, deep-learning analytics are poised to revolutionise the industry, and facilitate a leap in the capabilities of video analytics. In the last couple of years, there has been a marked increase in research and development in deep-learning neural networks, proving their capabilities, generating considerable excitement, and putting them within reach of a much wider user group.
Deep learning appears to be able to offer a level of accuracy and reliability in object and behaviour classification that not only enables video analytics finally to deliver on some of the lofty but as yet unrealised claims made in the past, but pushes capabilities far beyond them. Broadly speaking, there are two main areas in which deep learning analytics offer great benefits over the technology that has preceded it. They are: 1) Accuracy A long-held complaint levied against traditional analytics products was that their algorithms were unable to distinguish between objects and behaviours that a human being would have no problem classifying. This deficiency in computer vision algorithms results either in missed security breaches or false alarms. The ability of deep learning algorithms to view a scene intuitively, as a human viewer would, means that detection accuracy increases dramatically, while false alarm rates fall. Neural networks allow a computer to apply a series of assessments to a given situation. This is an important development for the video analytics industry. Although some end-users may not need an analytics solution that is 100% accurate 100% of the time, many use cases require that their security system be as close to infallible as possible. Users in the critical infrastructure sector, for instance, cannot afford to miss a breach in their security; and can spend a large amount of money investigating false alarms. Deep learning algorithms have shown they can learn to achieve 99.9% accuracy in certain tasks, where conventional systems would struggle to achieve 95%. In many security use cases, these few percentage points make all the difference. 2) Power Not only has deep learning demonstrated its capacity to increase radically the effectiveness of a computer to reliably classify objects and behaviour. It is also making possible the processing and analysis of increasing volumes of video footage in a fraction of the time of earlier analytics. Companies such as Avigilon, Qognify, and IronYun are now marketing analytics that leverage deep learning to turn vast amounts of video footage into usable information in a fraction of the time it would have taken in the past. Video processing software that allows users to interact with their surveillance footage using a Google-like interface and natural language search terms drastically reduces the time it takes to find relevant video footage in an archive that might store video from thousands of feeds. Facial recognition is an area that has benefited much from deep learning architecture. Indeed, most facial recognition analytics on the market today feature some kind of deep learning. Not only does deep learning increase the accuracy of facial recognition sensors, it also enables faces to be identified in larger and more crowded scenes. In the wake of recent terrorist attacks in crowded locations, this capability could radically change the whole approach to security monitoring, allowing law enforcement to track suspects with far greater speed and efficiency. Herta is one company that specialises in facial recognition in large crowds. The IHS Markit Video Analytics in Security and Business Intelligence Report – 2017 includes dedicated in-depth research into deep-learning video analytics market, and is available for purchase now  (출처: 인텔)
인텔이 독특한 제품을 조용히 등장시켰습니다. 모비디우스(Movidius) 신경망 컴퓨트 스틱(Neural Compute Stick, NCS)이 그것으로 USB 스틱형 코프로세서입니다. 목적은 이름처럼 신경망 연산 등 AI 관련 연산과 AR/VR 관련 연산을 하는 것입니다. 가격은 양심적인 79달러인데 과연 수요가 있을지는 잘 모르겠다는 생각입니다. 사실 사람들이 잘 몰라서 그렇지 신경망 컴퓨트 스틱은 이전에도 있었습니다. 2016년에 나온 Fathom이라는 물건으로 역시 모비디우스만큼이나 생소한 물건입니다. 아무튼 이 모비디우스 컴퓨트 스틱은 Myriad 2 VPU라는 생소한 GPU를 연산용으로 사용하고 있으며 TSCM의 28nm 공정으로 제조되었지만, 1W 당 100GFLOPS의 인공 지능 관련 연산을 수행할 수 있는 높은 전력 대 성능비를 가지고 있습니다. 다만 컴퓨트 스틱 형태로 개발된 점을 봐서도 알 수 있지만, 전력 소모는 2.5W 미만이며 절대 성능 자체가 높은 것은 아니라고 할 수 있습니다. 다만 그래픽 카드를 탑재할 수 없는 경량 노트북에서 인공 지능 및 관련 연산을 수행하는 경우 목적이라면 나름 유용하게 사용할 수 있을지도 모르겠습니다. 모비디우스는 USB 3.0 Type A을 사용하며 텐서플로 대신 Caffe라는 딥 러닝 프레임워크를 지원합니다. 4 GB LPDDR3 메모리를 사용하며 FP16 연산에 특화된 물건이라고 할 수 있습니다. 신기한 재주 가운데 하나는 여러 개의 모비디우스 스틱을 연결해 병렬 연산을 할 수 있다는 점으로 이를 Multi-Stage (stick) Multi-Task Convolutional Neural Network (MTCNN)라고 부릅니다. 일반 사용자는 좀처럼 쓸일이 없는 독특한 물건이지만, AI나 AR/VR이 강조되는 시대 상황에 맞춰 나온 물건이라고 생각합니다. 문제는 지금 인텔이 여기에 매달릴 상황이 아니라는 점이겠죠. 몇 년 사이 조금씩 성능을 향상시킨 CPU만 내놓으면서 인텔은 AMD에 추격을 허용했고 라이젠 출시 이후에는 서버 및 전문가 시장에서 우위를 잃어버릴 위기에 처했습니다. 새로운 시장에 도전하는 것도 좋지만 본래 주력 사업인 PC와 서버 부분을 놓치면 회사가 어려움에 처하게 될 것입니다. 아무래도 지금은 회사의 역량을 새로운 CPU를 개발하는 데 집중해야 할 시기일 것입니다. 참고 http://www.anandtech.com/show/11649/intel-launches-movidius-neural-compute-stick http://www.tomshardware.com/news/movidiud-myriad2-vpu-vision-processing-vr,30850.html [출처] 조용히 등장한 인텔의 인공지능 컴퓨트 스틱 - Movidius Neural Compute Stick|작성자 고든 제주도/ETRI/경찰청에서 추진하는 인공지능(AI)기반 CCTV 개발 계획 소식입니다.! 2019년 시범운용 목표로 개발이 된다고 합니다.! http://www.hkbs.co.kr/news/articleView.html?idxno=428089 http://www.yonhapnews.co.kr/bulletin/2017/06/14/0200000000AKR20170614159800056.HTML?input=1195m  http://www.cctvnews.co.kr/news/articleView.html?idxno=69587 http://www.hikvision.com/en/Press-Release-details_74_i1527.html 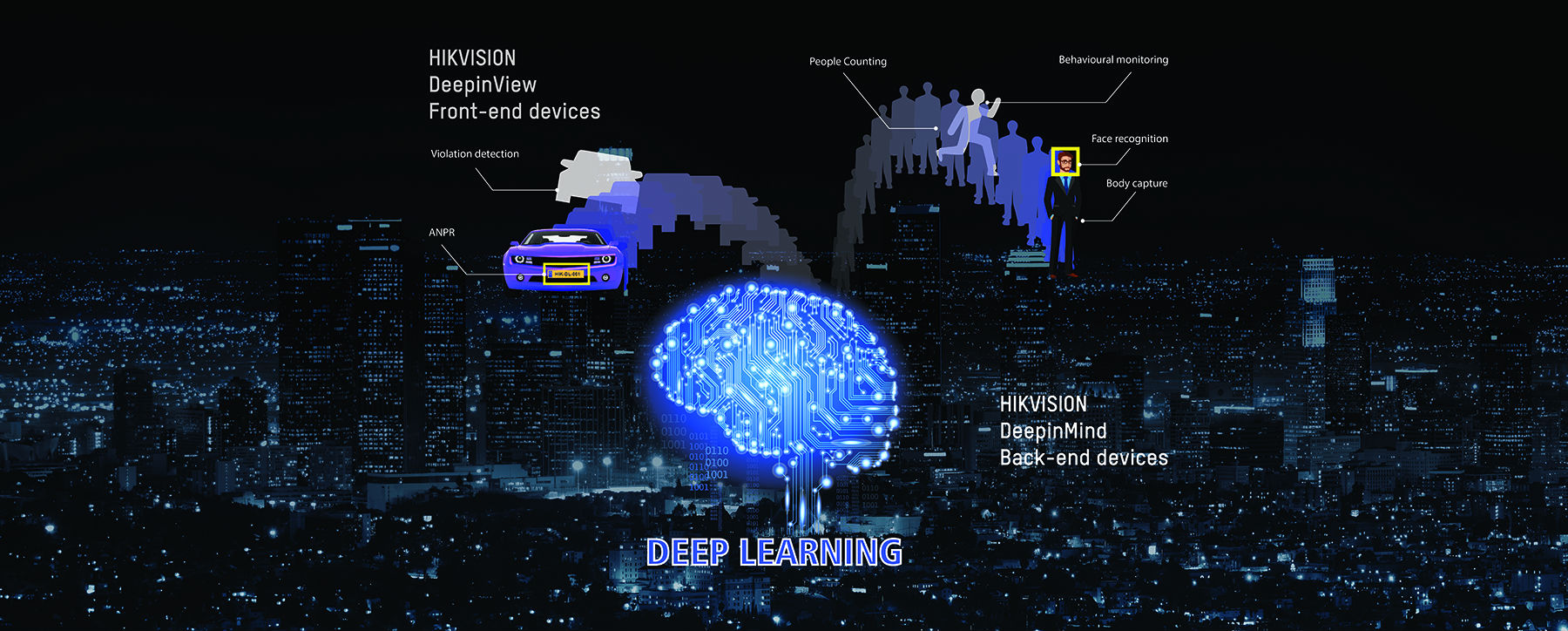 Deep Learning has swept through the IT industry, bringing benefits and better classifications to a number of applications. Inspired by the way the human brain works, the technology uses a layered learning process to enable the computer to classify, store and access data, which it can then refer to for learning. This means it can use a whole image to recognise, rather than relying on separate elements of that image. This is a cumulative process – the more elements it has to draw on, the better the classification – thus, the better the ‘learning’. The benefits of this technology for face recognition and image classification makes it hugely valuable in the field of security. It touches on every aspect of the security industry – from facial and vehicle detection to behaviour analysis. This, in turn, starts to change the focus of security from being reactive to being able to predict problems before they happen. Hikvision has taken this technology and innovated a family of products to maximise its use. The DeepInview IP camera range and the DeepInmind NVR range work together to provide all the power and benefits of Deep Learning. While the cameras provide the smart ‘eyes’ of the system, the NVR represents the analytic and storage capabilities of the brain. The products help to tackle security on two fronts – recognition, monitoring and counting of people and recognition and detection of vehicles. This uses Deep Learning technology at its most effective – for its ability to classify and recognise thousands of ‘features’. Obviously, this multi-layered approach uses a lot of memory and performance, which is one of the reasons why the technology has become much more widespread in the past few years. To put this into perspective, in the first stages of the technology, it took 1,000 devices with 16,000 CPUs to simulate a neural network. Now, just a few GPUs are needed. Hikvision is partnering with the largest of the chipset brands – Intel and nVidia – to explore the possibilities of Deep Learning for the surveillance industry. Hikvision’s innovation also facilitates and improves on this – the H.265+ codec radically reduces transmission bandwidth and data storage capacity requirements. This means there’s no loss of quality even though the data being shared and stored is exponentially higher. Applications are numerous. The technology could enable the system to provide a black list/white list alarm, for example, which could come in very handy in access control scenarios. It could also be used to recognise unusual behaviour – possibly allowing security staff to prevent an issue if people are found loitering nearby, for example. The new premium range of products will further extend the quality and capabilities of security systems. They will also allow security professionals to start planning to avoid issues, rather than reacting to them. This could be the next evolution of the whole industry – using AI to change the world, one Hikvision solution at a time. For more information, check out our article “How Deep Learning Benefits the Security Industry. Link here And keep an eye on the Hikvision website to see launches of the new DeepinView and DeepinMind products later this year 아래 소스 : https://sassec.wordpress.com/2017/07/31/hikvision-and-deep-learning/  Data storage devices across the security industry are routinely required to handle an enormous amount and many layers of raw data. As Safe City projects in varying sizes become more prevalent, the number of surveillance nodes has reached the hundreds of thousands. And due to the widespread use of high-definition monitoring, the amount of data involved in security surveillance has increased dramatically in a short time. Efficient collection, analysis, and application of data and the intelligent use of it are becoming ever more critical in this industry. Thus, improving video intelligence appears to be an inevitable, industry-wide goal.
Security users hope that their investment in new products will bring even more benefits beyond simply tracing and tracking persons of interest and evidence collection after a security event. Some examples of added benefits include using the latest technologies to replace the large amount of man-power previously required for searching surveillance footage, detecting anomalous data, and finding ever more efficient ways to allow surveillance to shift from post-incident tracing to alerts during incidents—or even pre-incident alerts. In order to satisfy these demands, new technologies are required. Intelligent video surveillance has been available for many years. However, the outcomes of its application have not been ideal. The emergence of deep learning has enabled these demands to become reality. The Insufficiency of Traditional Intelligent Algorithms Traditional intelligent video surveillance has especially strict requirements for a scene’s background. The accuracy of intelligent recognition and analysis in comparable scenarios remains inconsistent. This is primarily due to the fact that traditional intelligent video analysis algorithms still have many flaws. In an intelligent recognition and analysis process, such as human facial recognition, two key steps are required: First, features are extracted, and second, “classification learning” is performed. The degree of accuracy in this first step directly determines the accuracy of the algorithm. In fact, most of the system’s calculation and testing workload is consumed in this part. The features in traditional intelligent algorithms are designed by humans and have always been heavily subjective. More abstract features—those that humans have difficulty comprehending or describing—are inevitably missed. With shifting angles and lighting, and especially when the sample size is enormous, many features can be too difficult to detect. Therefore, while traditional intelligent algorithms perform well in very specific environments, subtle changes (image quality, environment, etc.) yield significant challenges to accuracy. The second step—classification learning—mainly involves target detection and attribute recognition. As the number of available categories for classification rises, so does the difficulty level. Hence, traditional intelligent analysis technologies are highly accurate in vehicle analysis but not in human and object analysis. For example, in vehicle detection, a distinction is made between a vehicle and a non-vehicle, so the classification is simple and the level of difficulty is low. To recognize vehicle attributes requires recognition of different vehicle designs, logos, and so on. However, there are relatively few of these, making the classification results generally accurate. On the other hand, if recognition is to be performed on human faces, each person is a classification of its own, and the corresponding categories will be extremely numerous—naturally leading to a very high level of difficulty. Traditional intelligent algorithms generally use shallow learning models to handle situations with large amounts of data in complex classifications. The analysis results are far from ideal. Furthermore, these results directly restrict the breadth and depth of intelligent applications and further development. Hence the need for increasing the “depth” of intelligence in big data for the security industry is arising. The Advantages of Deep Learning and its Algorithms Traditional intelligent algorithms are designed by humans. Whether or not they are designed well depends greatly on experience and even luck, and this process requires a lot of time. So, is it even possible to get machines to automatically learn some of the features? Yes! This is actually the objective of Artificial Intelligence (AI). The inspiration for deep learning comes from a human brain’s neural networks. Our brains can be seen as a very complex deep learning model. Brain neural networks are comprised of billions of interconnected neurons; deep learning simulates this structure. These multi-layer networks can collect information and perform corresponding actions. They also possess the ability for object abstraction and recreation. Deep learning is intrinsically different from other algorithms. The way it solves the insufficiencies of traditional algorithms is encompassed in the following aspects. First, From “Shallow” to “Deep” The algorithmic model for deep learning has a much deeper structure than the two 3-layered structures of traditional algorithms. Sometimes, the number of layers can reach over a hundred, enabling it to process large amounts of data in complex classifications. Deep learning is very similar to the human learning process, and has a layer-by-layer feature-abstraction process. Each layer will have different “weighting,” and this weighting reflects on what was learned about the images’ “components.” The higher the layer level, the more specific the components. Simulating the human brain, an original signal in deep learning passes through layers of processing; next, it takes a partial understanding (shallow) to an overall abstraction (deep) where we can perceive the object. Second, From “Artificial Features” to “Feature Learning” Deep learning does not require manual intervention but relies on a computer to extract features by itself. This way it is able to extract as many features from the target as possible, including abstract features that are difficult or impossible to describe. The more features there are, the more accurate the recognition and classification will be. Some of the most direct benefits that deep learning algorithms can bring include achieving comparable or even better-than-human pattern recognition accuracy, strong anti-interference capabilities, and the ability to classify and recognize thousands of features. Key Factors of Deep Learning In total, there are three main reasons why deep learning only became popular in recent years and not earlier: the scale of data involved, computing power, and network architecture. Improvements in data-driven algorithm performance have accelerated deep learning in various intelligent applications in a short amount of time. Specifically, with the increase in data scale, algorithmic performance improved as well. Accordingly, user experience has improved and more users are involved, further facilitating a larger scale of data. Video surveillance data makes up 60% of big data, and the amount is rising at 20% annually. The speed and scale of this achievement is due to the popularization of high definition video surveillance—HD 1080p is becoming more common, and 4K and higher resolutions are gradually being applied in many important applications. Hikvision has operated in the security industry for many years with its own research and development capabilities, employing large amounts of real video and image data as training samples. With a large amount of good quality data, and over a hundred team members to label the video images, sample data with millions of categories have been accumulated. With this large amount of quality training data, human, vehicle, and object pattern recognition models will become more and more accurate for video surveillance use. Furthermore, high performance hardware platforms enable higher computational power. The deep learning model requires a large amount of samples, making a large amount of calculations inevitable. In the past, hardware devices were incapable of processing complex deep learning models with over a hundred layers. In 2011, Google’s DeepMind used 1,000 devices with 16,000 CPUs to simulate a neural network with approximately 1 billion neurons. Today, only a few GPUs are required to achieve the same sort of computational power with even faster iteration. The rapid development of GPUs, supercomputers, cloud computing, and other high performance hardware platforms has allowed deep learning to become possible. Finally, the network architecture plays its own role in advancing deep learning. Through constant optimization of deep learning algorithms, better target-object recognition can be achieved. For more complex applications such as facial recognition or in scenarios with different lighting, angles, postures, expressions, accessories, resolutions, etc., network architecture will impact the accuracy of recognition, i.e., the more layers in deep learning algorithms, the better the performance. In 2016, Hikvision achieved the number one position in the Scene Classification category at the ImageNet Large Scale Visual Recognition Challenge 2016. The team from Hikvision Research Institute used inception-style networks and not-so-deep residual networks that perform better in considerably less training time, according to Hikvision’s experiments for training and testing. Furthermore, Hikvision’s Optical Character Recognition (OCR) Technology, based on Deep Learning and led by the company’s Research Institute, also won the first price in the ICDAR 2016 Robust Reading Competition. The Hikvision team substantially surpassed both strong domestic and foreign competitors in three word-recognition challenges, including born-digital images, focused scene text, and incidental scene text, demonstrating that the word recognition technology by Hikvision reached the world’s top level. Application of Deep Learning Products In the past two years, deep learning technology has excelled in speech recognition, computer vision, voice translation, and much more. It has even surpassed human capabilities in the areas of facial verification and image classification; hence, it has been highly regarded in the field of video surveillance for the security industry. In the application of intelligent video in target detection, tracking, and recognition, the rise of deep learning has had a profound influence. When applying those three functions, deep learning potentially touches upon every aspect of the security video surveillance industry: facial detection, vehicle detection, non-motor vehicle detection, facial recognition, vehicle brand recognition, pedestrian detection, human body feature detection, abnormal facial detection, crowd behavior analysis, multiple target tracking, and so on. These types of intelligent functions require a series of front-end surveillance cameras, back-end servers and other products which support deep learning algorithms. In small scale applications, front-end cameras can directly operate structured human and vehicle feature extraction, and tens of thousands of human facial images can be stored within the front-end devices to implement direct facial comparison, so as to reduce costs of communicating with a server. In large scale applications, front-end cameras can work with back-end servers. Specifically, the structured video task is handled by front-end devices, reducing the workload for back-end devices; matching and searching efficiency of back-end servers improve as well. This year, Hikvision will soon introduce a series of products with deep learning technology, such as the DeepInview Series cameras which can accurately detect, recognize, and analyze human, vehicle, and object features and behavior, and can be widely used in indoor and outdoor scenarios. Another of products worth mentioning is Hikvision’s DeepInmind Series of NVRs which incorporate advanced deep learning algorithms and imitate human thoughts and memory. The DeepInmind products feature an innovative NVR+GPU mode, retaining the advantages of traditional NVRs and additional structured video analysis functions, which together greatly improve the value of video. Deep learning is the next level of AI development. It is beyond machine learning where supervised classification of features and patterns are set into algorithms. Deep learning incorporates unsupervised or “self-learning” principles. Hikvision is developing this concept in its own analytics algorithms. Enhanced accuracy is the result of multi-layer learning and extensive data collection. Application of this algorithm into face recognition, vehicle recognition, human recognition, and other platforms will significantly advance the performance of analytics.  Phttp://www.nvidia.co.kr/object/deep-learning-institute-kr.html   Nvidia Jetson TX1 running !! TX1 with 256 CUDA Core CPU  Deep learning 관련 기술 문의가 AXXON으로도 계속 오고 있고 관련 기사와 정보가 쏟아져 나오고 있습니다. 관련 자료를 보고 학습을 하면서 좋은 자료들과 정보들 나누기 위해서 BLOG내의 공간을 하나 더 만들어 봤습니다. 막연하게 스스로 학습한다는 Deep learning (딥러닝) 의 무엇인가를 알아보려고 하는 시점에 아래 영상을 보게 되었습니다. 7월 13일 EBS 지식채널e 통해 본 "벽속의 구멍 프로젝트"는 2007 년 2월 TED에 이 프로젝트를 진행한 교수( Sugata Mitra) 에 의해서 소개 되었다고 합니다. (https://www.ted.com/talks/sugata_mitra_shows_how_kids_teach_themselves) 2013년 TED Prize를 받으며 더 알려지지 않았나 싶습니다. 빈민가 아이들이 벽틈에 설치된 컴퓨터를 놓고 스스로 학습하고 학습한 결과를 다른 아이들에게 스스로 학습하고 배우고 전파하는 능력에 대한 성과와 거리와 장소를 벗어난 "Cloud School"을 소개 합니다. 다른 그리고 비슷한 관점이지만,, 이렇게 스스로 학습하는 인간의 능력이 computer 라는 tool을 통해 극대화 되는 것 이상으로 계산기에 불과할 수 있는 Computer가 스스로 학습하고 발전하는 원리가 Deep learning의 그것이 아닌가 생각하며 이 Blog 공간을 채워가 봅니다.  |
AuthorAxxonsoft Korea Archives
January 2023
Categories |


 RSS Feed
RSS Feed